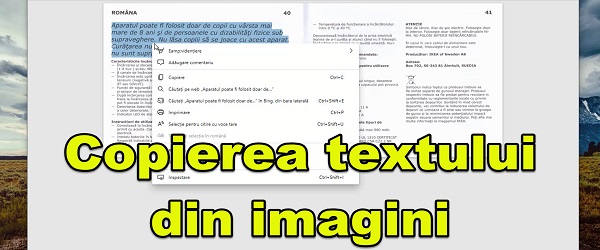
О чем видеоурок по копированию текста с изображений и отсканированных изображений на румынском языке?
Если вы когда-либо намеревались скопировать текст из отсканированных документов или скопировать текст с изображений, учебник «Копирование текста из изображений и сканирование на румынском языке» для вас.
OCR на румынском языке - Копирование текста с изображений и отсканированных изображений
На уровне программ OCR (оптического распознавания символов) для румынского языка у нас довольно тонкая поддержка, особенно для бесплатных программ для ПК.
К счастью, я нашел программу, которая может распознавать письмо на румынском языке и превращать его в копируемый текст.
Я говорю копируемый, потому что, очевидно, теряется форматирование документа. Мы можем только копировать текст, но не редактировать текст в изображении или PDF, сделанном из отсканированных изображений или изображений.
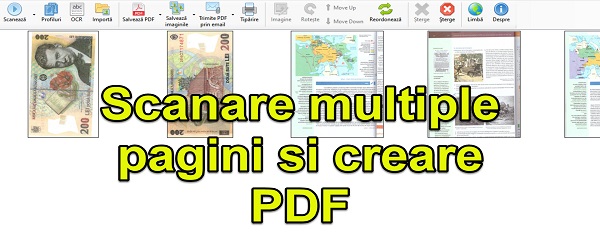
NAPS2 снова приходит нам на помощь с оптическим распознаванием текста на румынском языке. После учебник, в котором я показал вам, как превратить сканеры со сканера или любые другие изображения в PDF, теперь мы увидим возможность OCR с поддержкой румынского языка этого бесплатного программного обеспечения для Windows.
Что означает OCR?
OCR - это сокращение от «оптического распознавания символов». Это означает программное обеспечение OCR умеет распознавать символы (числа, буквы, знаки препинания) и преобразовывать их из изображения с аналоговой информацией в цифровые символы, которые можно скопировать и использовать в другом документе.
Для чего используется OCR?
OCR, особенно если в программе есть поддержка румынского языка, можно использовать для:
- извлечение цитат из печатных книг на бумаге.
- Преобразование текста из печатного в цифровой.
- Распознавание и перевод знаков на иностранные языки (Google Lens)
- Распознавание и последующий перевод инструкций в руководствах пользователя
- Оцифровка любой печатной информации для онлайн-распространения
- и т. д. и т. д.
Как мы используем функцию OCR в программе NAPS2?
Все очень просто.
Перед сканированием нам нужно активировать функцию OCR, и программа обо всем позаботится. Наконец, вы создадите PDF-файл, из которого вы сможете скопировать текст.
Скачать NAPS2 - бесплатная программа для создания PDF-файлов из изображений или отсканированных изображений с поддержкой OCR на румынском языке.
Другие видеоуроки с оптическим распознаванием текста, PDF, сканированием и т. Д .:







Я не хочу быть плохим, но как это на 4 странице на английском и 40 на румынском? OCR у меня не работает. Можно ли запустить OCR в случае импортированных PDF-файлов?
Извините, я не знаю, почему я подумал, что он переводит.
Программа не работает: ((
Я использую ABBYY FineReader уже много лет, он отлично распознает румынский язык и мне кажется более эффективным и быстрым в использовании, чем то, что вы нам представили!…
Очень хорошо !, форматирование не сохраняет, но текст важен, спасибо